Latest Project
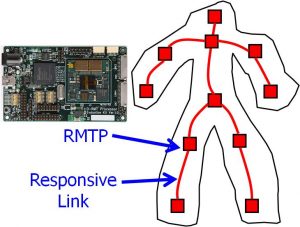
Space Responsive Multithreaded Processor I (SRMTP )
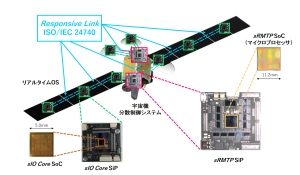
In this project, we have been researching and developing distributed real-time systems for spacecraft control. The technical term ‘real-time’ means that processing and communication have time constraints including deadlines, cycles, etc. A distributed real-time system works only if its processing and communication meet the time constraints. For example, if the motor control process in a system does not meet the time constraint, the system cannot operate normally and may cause an accident. Furthermore, a spacecraft system operating in outer space environment is required to continue operating even under the influence of cosmic radiation, vibration, heat, etc. In order to achieve distributed control for spacecraft, we have researched and developed an SoC (System-on-Chip) that integrates a real-time processing CPU, real-time communication, memory, control I/O, etc. in a single-chip LSI. We are also conducting research and development on SiP (System-in-Package), which is an ultra-small board that integrates the SoC, DRAM, Flash, connectors, etc., and a real-time OS (favor). Specifically, sRMTP (Space Responsive Multithreaded Processor) for highly functional distributed real-time control integrates RMT PU (Responsive Multithreaded Processing Unit), real-time communication Responsive Link (ISO/IEC 24740), embedded SRAM and DRAM controller with error correction function, and various I/O peripherals (UART, PWM, GPIO, etc.) in a single-chip SoC. The RMT PU can achieve fine-grained real-time processing by the unique special functions including simultaneous multithreaded execution with priority, IPC control mechanism to control the speed of each program, context cache to reduce the overhead of context switch, thread wakeup mechanism by the corresponding interrupt, etc. Responsive Link can communicate among multiple nodes in any topology, and each node can transmit packets according to the priority given to the packet, so preemptive real-time communication can be performed. In addition, sIO core is an SoC that integrates a simple CPU, Responsive Link, and various control I/O peripherals on a single chip, making it possible to easily build a relatively simple distributed control node. These sRMTP and sIO core are designed to have system level, architecture level, and process level dependability, and achieve multi-level dependability. Our technologies are applicable not only to spacecraft but also to any distributed real-time system.

Hardware Group
Dependable Responsive Multithreaded Processor I (D-RMTP I)
A distributed real-time system is a computer system that integrates a set of software or hardware components designed for specific control functions with time constraints, such as automobiles, factory automations, spacecraft, and humanoid robots. These applications are built upon various key technologies including real-time processing architecture, real-time inter-node communication, and real-time operating system. Dependability is also becoming more and more important in these systems since they have already been used as a part of social infrastructure. We have designed D-RMTP (Dependable Responsive Multithreaded Processor) SoC and SiP especially for humanoid robots. They are used as control processors of humanoid robots, in which these control processors are embedded into their joints for the motion control. The following figures illustrate architecture of the D-RMTP SoC that integrates a real-time processing unit (RMT PU), Responsive Link for a real-time inter-node communication, and various I/O peripherals including IEEE1394, PCI-X, Ethernet, PWM generators, SPI, and so on. For more details, please refer to Suito et.al., 2012. The D-RMTP SoC, DDR-SDRAM, flash memory, power supply circuit, and various sensors are stacked and implemented in a 30mm x 30mm D-RMTP SiP (shown in the following figure), since small footprint size is highly required for practical embedded systems, such as humanoid robots. 



Responsive Link
Responsive Link is an inter-node communication standard (ISO/IEC 24740:2008) for distributed real-time systems, such as an inter-processor network in a humanoid robot. Responsive Link defines physically-separated links for two link types: Event Link for small and low-latency communication with hard real-time constraints and Data Link for high-throughput communication for soft real-time constraints. Priority-based arbitration allocates a crossbar switch based on priority of packets when multiple packets request the same output port so that the highest-priority packet always goes first followed by lower-priority packets. Priority-based routing defines a routing table entry for each pair of destination and priority so that different routing paths can be assigned for packets destined to the same node but with different priority levels. In addition, various Error Checking and Correction (ECC) codes and line codes are implemented, in order to improve dependability of communication. Since communication environment and noise parameters are changed dynamically (e.g., motor vehicles and robots), an optimal combination of ECC code and line code is selected dynamically in response to the priority and noise parameters.


Instructions Per Clock cycle (IPC) Control Method for Real-time Systems
Real-time execution of applications is one of key requirements for many embedded systems used for our infrastructure, such as consumer appliances, transportation systems, and robots. Although such real-time scheduling relies on worst-case execution time (WCET) of tasks, the WCET analysis is increasingly pessimistic due to the complexity of recent systems (e.g., SMT, OoO, and DVFS). Such pessimistic WCET analysis decreases the application performance. Thus, we propose an alternative approach that does not rely on the WCET analysis but directly controls instruction per clock cycle (IPC) of tasks. That is, we can specify the target IPC for each task, and a microprocessor with the proposed IPC control mechanism commits the instructions so that the target IPC is satisfied. Feed-forward or Proportional-integral-derivative (PID) is used for the IPC control and a dynamic error calibration is used for improving the accuracy. The IPC control mechanism was implemented on RMT Processor and its practicality has been validated with RMTP evaluation board. For more details, please refer to Matsumoto et.al., 2011. 

Real-Time Network-on-Chips (RT-NoCs)
With advances in fabrication technology, the number of cores on chip multi-processors (CMPs) increases and conventional interconnection fabrics, such as buses, cannot provide enough scalability for large-scale CMPs. Network-on-Chips (NoCs) are widely used as scalable interconnects for large-scale CMPs. Priority-aware NoCs that transfer packets based on their priority are required for supporting Quality of Service (QoS) and guaranteeing real-time constraints on CMPs. Although packets are processed exactly with their priority for low workload, priority inversions that block high-priority packets with low-priority ones are introduced for high workload. In this case, the communication latency of higher-priority packets is increased by lower-priority ones. Thus, Priority Inheritance (PI) method and Virtual Channel Stealing (VCS) method are proposed for reducing priority inversions and evaluated in terms of hardware cost and network performance. The evaluation results show that VCS method improves the communication latency of highest-priority packets and reduces priority inversions.
Dependable Responsive Multithreaded Processor II (D-RMTP II)
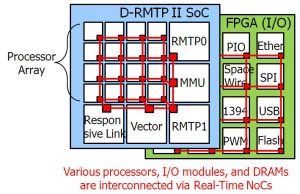
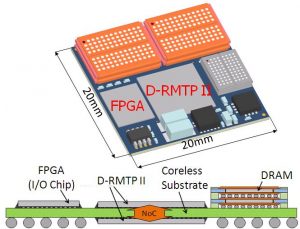
Heterogeneous multi-core architecture that consists of processors, memory modules, and I/O devices with various sizes, functions, and speeds is one of attractive solutions for high-performance embedded systems, such as humanoid robots. D-RMTP II is the next generation of D-RMTP I that supports such heterogeneous multi-core features. D-RMTP II SiP consists of D-RMTP II SoC chips, DRAM chips, and a dedicated I/O controller chip. D-RMTP II SoC integrates RMT processors (RMTP0 and RMTP1), Parallel processor array (16 MIPS-like processors), Vector processor, and Responsive Link controller. I/O Chip has various I/O controllers, such as IEEE1394, PCI-X, Ethernet, PWM generators, and SPI. D-RMTP II SoC is implemented as ASIC with a 65nm process technology and I/O Chip is implemented on FPGA. All of them are interconnected with real-time on-chip and inter-chip networks. In parallel with the SoC and SiP development, we have been investigating key technologies for such heterogeneous multi-core architecture, such as distributed TLB (Translation-Lookaside Buffer) mechanism for efficient memory management, dedicated I/O processor, and so on.


Related Publications
- Kazutoshi Suito, Rikuhei Ueda, Kei Fujii, Takuma Kogo, Hiroki Matsutani and Nobuyuki Yamasaki, “The Dependable Responsive Multithreaded Processor for Distributed Real-Time Systems,” IEEE Micro, Vol. 32, No. 6, pp. 52-61, December, 2012.
- Nobuyuki Yamasaki, “Responsive Link for Distributed Real-Time Processing,” Proc. of the 10th International Workshop on Innovative Architecture for Future Generation High-Performance Processors and Systems (IWIA’07), pp.20-29, Jan 2007.
- Kohei Matsumoto, Hiroyuki Umeo, and Nobuyuki Yamasaki, “A Thread Speed Control Scheme for Real-time Microprocessors,” Proc. of the 1st International Workshop on Cyber-Physical Systems, Networks, and Applications (CPSNA’11), pp.21-16, Aug 2011.
- Masakazu Taniguchi, Hiroki Matsutani, and Nobuyuki Yamasaki, “Design and Implementation of On-chip Adaptive Router with Predictor for Regional Congestion,” Proc. of the 1st International Workshop on Cyber-Physical Systems, Networks, and Applications (CPSNA’11), pp.22-27, Aug 2011.
- Nobuyuki Yamasaki, “Co-Design of Dependable Responsive Multithreaded Processor II (DRMTP-II) SoC and SiP,” The International Workshop on Innovative Architecture for Future Generation High-Performance Processors and Systems (IWIA) 2014, March 2014.
- Kawase Daiki, Kazutoshi Suito, Hiroki Matsutani, and Nobuyuki Yamasaki, “Design and Implementation of Distributed TLB Mechanism for Heterogeneous Multi-Core Processors,” IEICE Technical Reports CPSY2011-84 (ETNET’12), Vol.111, No.461, pp.85-90, Mar 2012.
Software Group
Real-Time Scheduling Theory
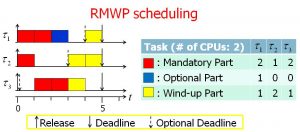
Distributed real-time systems, such as humanoid robots, have been encountering overloaded conditions in dynamic environments. To improve their quality of service (QoS) while keeping the time constraints, we propose a practical imprecise computation model that defines critical and real-time parts (e.g., mandatory and wind-up parts) and non-critical and non-real-time parts (e.g., optional parts) which are not executed to avoid a deadline miss under the overloaded conditions. A real-time scheduling algorithm that supports the practical computation model, called RMWP (Rate Monotonic with Wind-up Part), is proposed and applied to both single- and multi-processor environments. The schedulability analysis proves that the proposed real-time scheduling algorithm can complete tasks by their deadlines theoretically if and only if a specific condition (e.g., deadline, period, worst case execution time and CPU utilization) is satisfied. Our research interest includes the explanation of the real-time scheduling algorithm and computation model for such distributed real-time systems.

Real-Time Scheduling Analysis
We have been evaluating wide range of real-time scheduling algorithms through simulations and experiments using real machines. The simulations are performed to evaluate the theoretical capacities of real-time scheduling algorithms based on success ratio. The experiments are performed to evaluate the scheduling overhead on the real machines with real-time operating systems. The overhead affects the success ratio significantly, and it depends on hardware architecture (e.g., IBM x3755 48 CPUs), ready queue (e.g., O(1) scheduler, binomial heap queue, and double circular linked list), real-time scheduling algorithm (e.g., RM, EDF, and RMWP), and scheduling policy (e.g., global, partitioned, semi-partitioned, and cluster). Our research interest includes the detailed performance analysis of the scheduling algorithms on practical distributed real-time systems, such as humanoid robots.


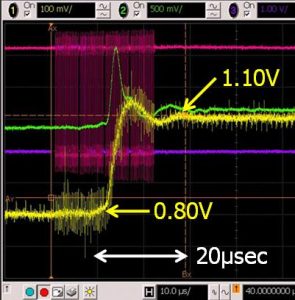
Real-Time Dynamic Voltage and Frequency Scaling (RT-DVFS)
Recent embedded real-time systems, such as mobile phones and humanoid robots, require not only real-time constraints but also low power consumption and high performance. Dynamic voltage and frequency scaling (DVFS) technique that dynamically adjusts the supply voltage and frequency has been used for various systems in order to improve the energy efficiency. However, DVFS introduces time and energy overheads when the voltage and frequency are changed at run-time (i.e., voltage transition latency and energy). In particular, the voltage transition latency is a serious problem for the embedded real-time systems with strict time constraints. We have proposed a real-time DVFS (RT-DVFS) technique that can guarantee the time constraints by taking into account the voltage transition latency. Actual voltage transition latency and energy overhead are essential parameters for such RT-DVFS, so we have measured the voltage transition latency and energy overhead on the RMT Processor evaluation board. The proposed RT-DVFS technique has been evaluated through simulations using the measured parameters and practical experiments using the RMT Processor evaluation board. The results show that the proposed RT-DVFS technique achieves favorable scheduling success ratio even with the voltage transition overheads.



Real-Time OS for RMT Processor
Real-time operating systems based on ITRON specification have been widely used in Japanese industries. We extend an ITRON-based OS to improve the performance and predictability by using RMT Processor specific features. For example, thread-control instructions, which are specific to RMT Processor, are used for thread creation and dispatch for reducing the context switching overhead. A dedicated thread is assigned to interrupt processing in order to maintain the worst-case interrupt response time when the number of threads executed simultaneously increases. Experiment results using RMT evaluation board show that although the multithread extension typically increases the kernel code size and execution time, service calls that include context switch operations are accelerated by the hardware-assisted context switch. In addition, task schedulability is improved by the fast context switching by using the thread-control instructions.
Real-Time Communication Scheduling
Real-time communication network is the heart of distributed system that integrates a set of software or hardware components with time constraints. For example, in modern humanoid robots, several dozen of control processors are embedded into their joints for the motion control. Thus, real-time communication that can guarantee given communication deadlines with priority-based arbitration between these control processors is essential for the precise motion control. D-RMTP with Responsive Link has been designed for such purpose. Communication deadline and its priority are determined for each source and destination nodes pair, depending on communication requirements of the motion control. We have been studying real-time communication scheduling algorithms that can maximize the communication schedulability without violating the given deadlines. We are now planning to apply the proposed real-time communication scheduling algorithms for real humanoid robots.



Related Publications
- Hiroyuki Chishiro and Nobuyuki Yamasaki, “Global Semi-fixed-priority Scheduling on Multiprocessors,” Proc. of the 17th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA’11), pp.218-223, Aug 2011.
- Hiroyuki Chishiro and Nobuyuki Yamasaki, “Experimental Evaluation of Global and Partitioned Semi-Fixed-Priority Scheduling Algorithms on Multicore Systems,” Proc. of the 15th IEEE International Symposium on Object/Component/Service-Oriented Real-Time Distributed Computing (ISORC’12), pp.127-134, Apr 2012.
- Kei Fujii, Hiroyuki Chishiro, Hiroki Matsutani, and Nobuyuki Yamasaki, “Dynamic Voltage and Frequency Scaling for Real-Time Scheduling on a Prioritized SMT Processor,” Proc. of the 1st International Workshop on Cyber-Physical Systems, Networks, and Applications (CPSNA’11), pp.9-15, Aug 2011.
- Rikuhei Ueda, Kei Fujii, Hiroyuki Chishiro, Hiroki Matsutani, and Nobuyuki Yamasaki, “An Extension of Real-Time OS for Multithreaded Processors,” Proc. of the 18th IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS’12), Work-In-Progress session, Apr 2012. (to appear)
- Osamu Yoshizumi, Hiroki Matsutani, and Nobuyuki Yamasaki, “Packet Routing for Distributed Real-Time System on Real-Time Communication Link,” Proc. of the 28th ISCA International Conference on Computers and Their Applications (CATA’13), pp. 197-204, March, 2013.
- Yusuke Kumura, Kazutoshi Suito, Hiroki Matsutani and Nobuyuki Yamasaki, “A Low-Power Link Speed Control Method on Distributed Real-Time Systems,” 2013 IEEE 7th International Symposium on Embedded Multicore Socs, pp. 49-54, September, 2013.